00:00:00
MySQL 函数
一般函数
AVG函数求平均值
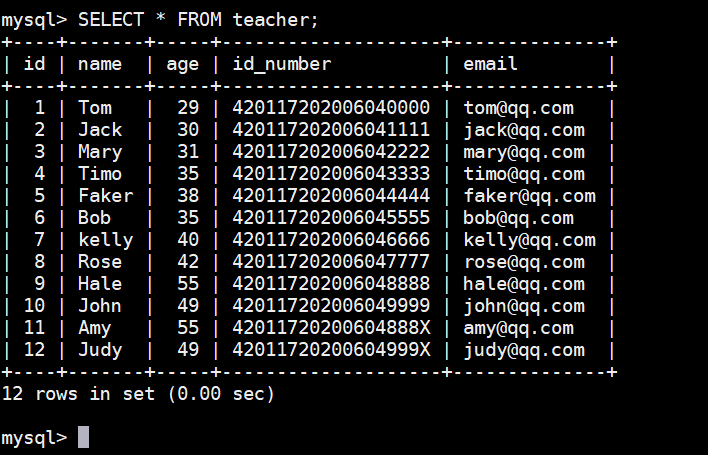
以 teacher 表为例,先查所有 teacher 信息:
sql
SELECT \* FROM teacher;查询结果如下图:
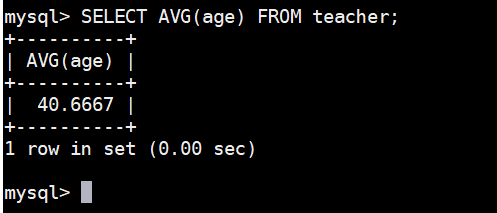
可以使用 AVG() 函数求出全部教师平均年龄:
sql
SELECT AVG(age) FROM teacher;执行结果如下图:
COUNT函数统计总条数
sql
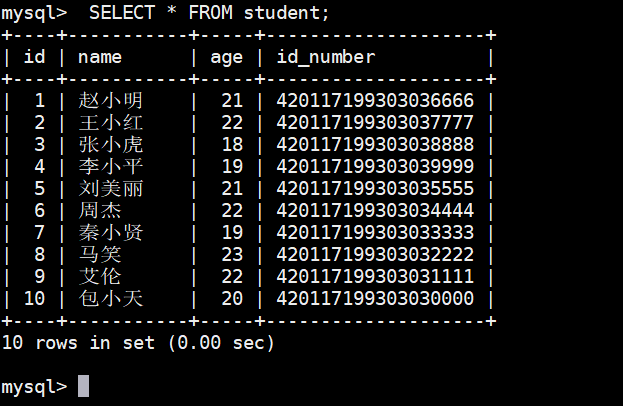
SELECT \* FROM student;查询结果如下图:
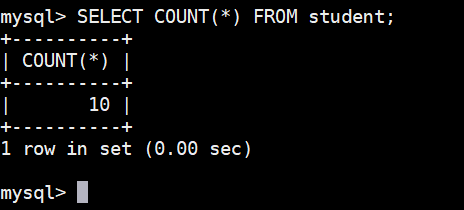
可以使用 COUNT() 函数统计全部学生数量:
sql
SELECT COUNT(\*) FROM student;执行结果如下图:
也可以对某一列使用 COUNT() 函数:
sql
SELECT COUNT(id) FROM teacher;执行结果如下图:
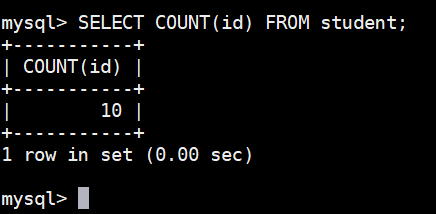
COUNT(*) 或者 COUNT(id) 表示统计全部结果集条数 10,注意 COUNT() 函数也会对 NULL 值的数据进行统计
SUM函数统计总和
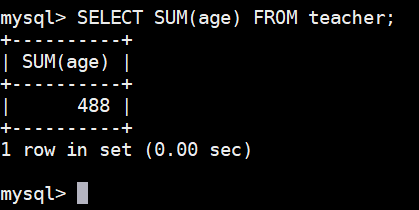
以 teacher 表为例,获取所有教师年龄总和:
sql
SELECT SUM(age) FROM teacher;执行结果如下图:
MIN函数取最小值
以 teacher 表为例,先查所有 teacher 信息:
sql
SELECT \* FROM teacher;查询结果如下图:
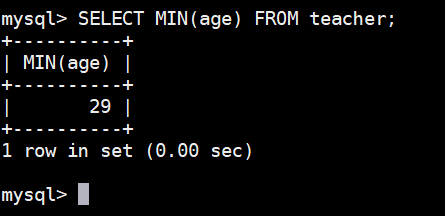
可以使用 MIN() 函数对结果集取年龄最小值的数据:
sql
SELECT MIN(age) FROM teacher;执行结果如下图:
MAX函数取最大值
sql
SELECT \* FROM student;查询结果如下图:
可以使用 MAX() 函数对结果集取年龄最大值的数据:
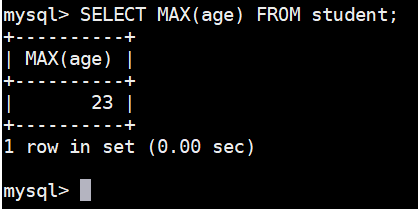
sql
SELECT MAX(age) FROM student;执行结果如下图:
条件判断函数
IF函数
以 student 表为例,使用 IF() 函数对查询结果的字段判断:
sql
SELECT name,IF(age > 17,'成年','未成年') AS age_group,id_number FROM student;查询结果如下图:
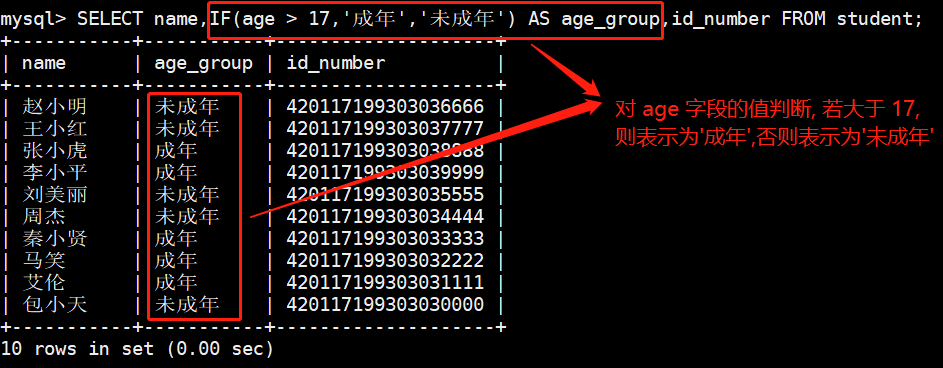
IF(age > 17,'成年','未成年') 表示若 age 字段满足 age > 17 则展示为 成年,否则展示为 未成年
IFNULL函数
先向 teacher 表插入测试数据:
sql
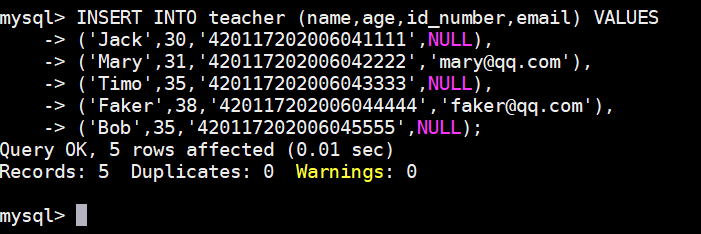
INSERT INTO teacher (name,age,id_number,email) VALUES
('Jack',30,'420117202006041111',NULL),
('Mary',31,'420117202006042222','mary@qq.com'),
('Timo',35,'420117202006043333',NULL),
('Faker',38,'420117202006044444','faker@qq.com'),
('Bob',35,'420117202006045555',NULL);执行结果如下图:
使用 IFNULL() 函数对查询结果的字段判断:
sql
SELECT name,age,id_number,IFNULL(email,'default@qq.com') AS full_email FROM teacher;执行结果如下图:
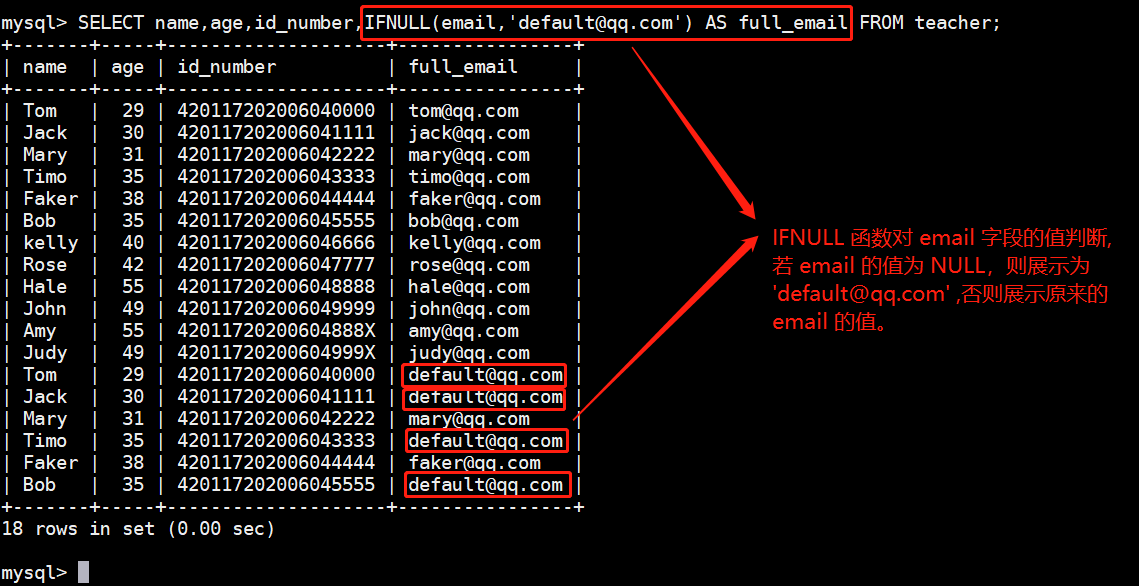
FNULL(email,'default@qq.com') 表示若 email 字段为 NULL ,则展示为 default @qq.com。
CASE条件判断
以 teacher 表为例,将指定英文名对应的中文名展示出来:
sql
SELECT
\*,
CASE name
WHEN 'Tom' THEN '汤姆'
WHEN 'Jack' THEN '杰克'
WHEN 'Mary' THEN '玛丽'
WHEN 'Timo' THEN '提莫'
WHEN 'Bob' THEN '鲍勃'
WHEN 'Judy' THEN '朱蒂'
ELSE '未定义' END AS 'chinese\_name'
FROM teacher;执行结果如下图:
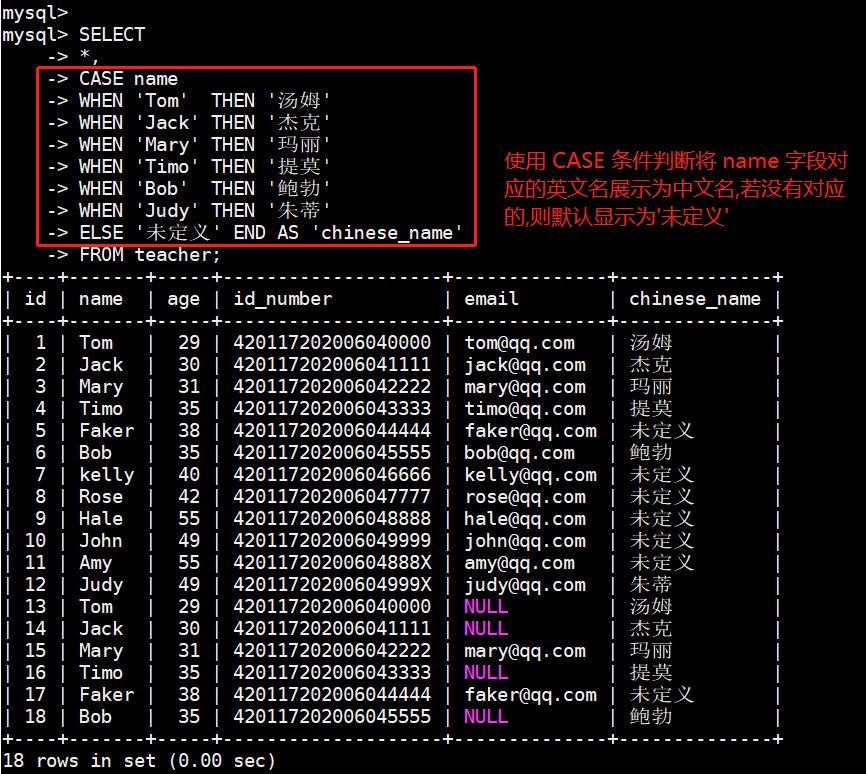
如上图所示, 对 name 字段进行条件判断,并将判断后的列重命名为 chinese_name,若指定的 name 字段的值满足 WHEN 则展示相应的 THEN后面的值
系统函数
| 函数名 | 说明 |
|---|---|
CONCAT(str0, str1) | 将两个字段的值拼接在一起 |
CONCAT_WS("拼接符", str0, str1) | 将两个字段的值使用指定拼接符拼接在一起 |
GROUP_CONCAT(expr) | 将指定分组的字段内容拼接在一起 |
UPPER(str) | 将字符串包含的英文字符小写转化成大写 |
LOWER(str) | 将字符串包含的英文字符大写转化成小写 |
INITCAP(str) | 将字符串的首字母变成大写 |
LENGTH(str) | 获取字符串的长度 |
SUBSTR(str FROM pos FOR len) | 截取字符串,其中 pos 表示起始位置,len 表示长度 |
TRIM(str) | 去除字符串两边空格 |
INSTR(str, substr) | 查找指定字符在字符串中的位置,其中 substr 表示需要查找的字符 |
LPAD(str, len, padstr) | 左填充,其中 len 表示字符串总长度,padstr 表示填充的字符 |
RPAD(str, len, padstr) | 右填充,其中 len 表示字符串总长度,padstr 表示填充的字符 |
LEFT(str, len) | 取一个字符串的前多少位 |
RIGHT(str, len) | 取一个字符串的后多少位 |
CEIL(X) | 向上取整 |
FLOOR(X) | 向下取整 |
MOD(N, M) | 取余,例如 MOD(age, 5),将字段 age 除以 5,除不尽的取余数 |
POWER(X, Y) | 幂运算,例如 POWER(age, 2),获取字段 age 的 2 次方的值 |
NOW() | 获取当前日期和时间 |
CURDATE() | 获取当前日期,不包含时间 |
CURTIME() | 获取当前时间,不包含日期 |
YEAR(now()) | 获取当前的年份 |
HOUR(NOW()) | 获取当前时间的小时数 |
MINUTE(now()) | 获取当前时间的分钟数 |
SECOND(NOW()) | 获取当前时间的秒数 |
MONTHNAME(now()) | 获取当前日期的英文月份 |
MONTH(NOW()) | 获取当前日期的数字月份 |
DATE_ADD(date, INTERVAL expr unit) | 查询日期的变化,例如 DATE_ADD('2020-03-03', INTERVAL 10 DAY) 表示 2020-03-03 十天之后的日期 |
DATEDIFF(expr1, expr2) | 日期差,例如 DATEDIFF('2019-12-29', '2019-12-01') 表示 2019-12-29 距离 2019-12-01 的天数 |
DATE_FORMAT(date, format) | 将指定日期转化为自定义格式,例如 DATE_FORMAT('2019-12-29', '%m/%d/%y') |
STR_TO_DATE(str, format) | 将指定字符串转化为日期格式,例如 STR_TO_DATE('12-29-2019', '%m/%d/%y') |
MD5(str) | 对字符串进行 MD5 转换 |
UNIX_TIMESTAMP() | 将指定日期转化为时间戳 |
COUNT() | 获取查询结果集条数 |
AVG(expr) | 获取指定列平均值 |
SUM(expr) | 获取指定字段值的总和 |
MIN(expr) | 获取指定字段值的最小值 |
MAX(expr) | 获取指定字段值的最大值 |
CONCAT 拼接字段
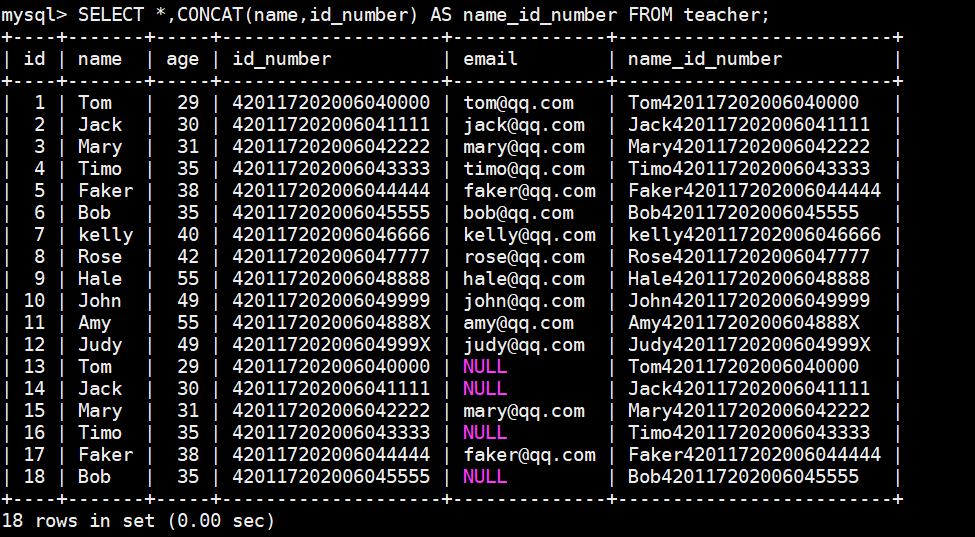
以 teacher 表为例,将教师信息的 name 和 id_number 字段的值拼接在一起:
sql
SELECT \*,CONCAT(name,id_number) AS name_id_number FROM teacher;查询结果如下:
GROUP_CONCAT拼接分组字段
以 course 和 teacher 表内连接分组为例,并使用 GROUP_CONCAT 将指定的分组字段拼接在一起:
sql
SELECT c.teacher_id,t.\*,GROUP_CONCAT(c.id) AS new_str
FROM course c
LEFT JOIN teacher t
ON c.teacher_id=t.id
GROUP BY c.teacher_id;查询结果如下:
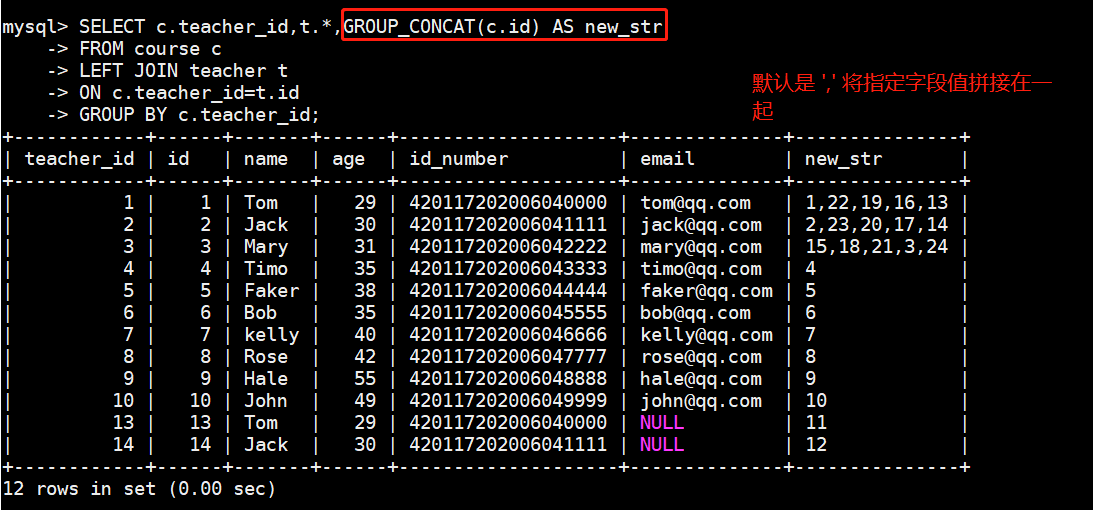
其中 new_str 的值是 GROUP_CONCAT() 函数将 c.id 的值拼接在一起,默认是 ‘,’ 拼接
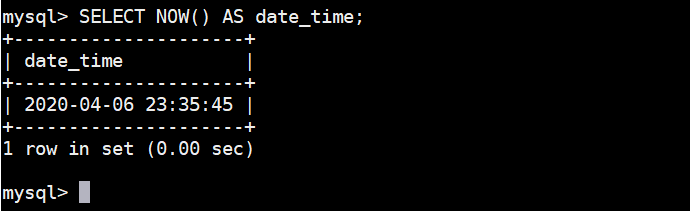
NOW()获取当前日期和时间
sql
SELECT NOW() AS date_time;获取结果如下图:
UNIX_TIMESTAMP()将日期转化为UNIX时间戳
将当前时间转化为 UNIX 时间戳:
sql
SELECT UNIX_TIMESTAMP();获取结果如下图:
其中 UNIX_TIMESTAMP() 函数默认获取当前时间戳,也可以获取指定日期的时间戳,例如 UNIX_TIMESTAMP('2012-12-21') 的取值为 1356019200。
值转化为大写字母
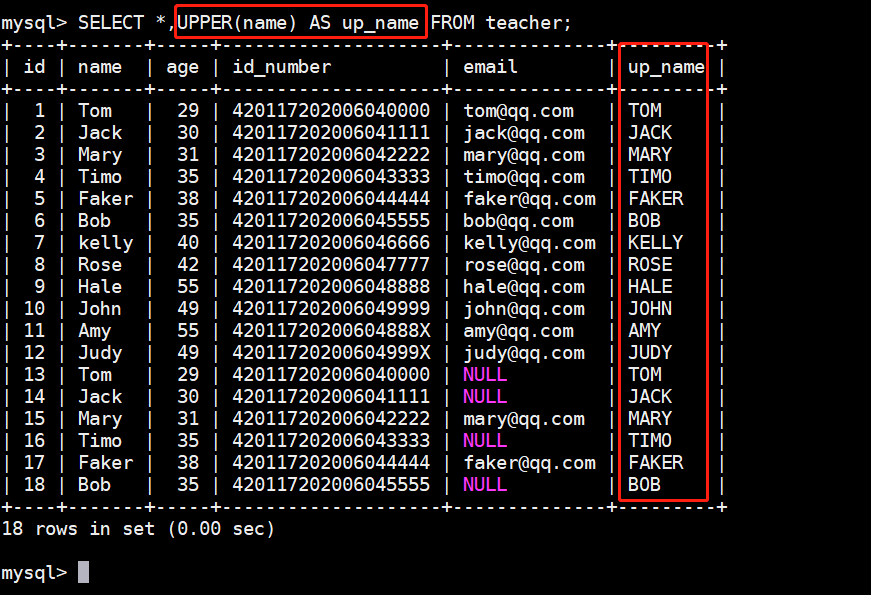
将 teacher 表 name 字段查询出来的值转化为大写字母:
sql
SELECT \*,UPPER(name) AS up_name FROM teacher;查询结果如下图: