00:00:00
MySQL 数据表设计
学习如何新建数据表,其中包括学生信息 student,教师信息表 teacher,学科表 course,学生选课表 student_course,合理选择字段类型。
一个数据表主要包含信息有 : 表名、主键、字段、数据类型、索引。
新建 “item_name” 数据库命令如下 :
sql
CREATE DATABASE item_name;新建数据库之后选择数据库:
sql
USE item_name;1. 数据表命名规范
数据表命名是小写字母和下划线 _组成,用来分割不同单词之间的含义,例如 “student_course” 表示学生选课关联表,实际命名需要根据具体功能而定,好的命名规范在实际工作中也是很重要的。
2. 新建学生信息表 student
2.1 确定字段
| 字段名称 | 含义 |
|---|---|
| id | 自增主键 |
| name | 学生姓名 |
| age | 学生年龄 |
| id_number | 身份证号 |
2.2 选择字段的数据类型
| 字段名称 | 数据类型 |
|---|---|
| id | 无符号整型(UNSIGNED INT) |
| name | VARCHAR(50) |
| age | UNSIGNED INT |
| id_number | VARCHAR(18) |
一般来说姓名字段的长度为 2-4 个字符,但是考虑到少数民族的学生姓名比较长,所以将姓名字段的长度设置为 50,适当的给的大一点。身份证号同样使用字符串类型来存储,因为有的身份证号中有字母。身份证的长度统一都是 18 位不变,直接在这里写死就好。
2.3 新建数据表
命令 :
sql
CREATE TABLE `student` (
`id` int(10) UNSIGNED NOT NULL AUTO\_INCREMENT,
`name` varchar(50) NOT NULL DEFAULT '无名',
`age` int(10) UNSIGNED NOT NULL DEFAULT 0,
`id_number` varchar(18) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
);NOTE
其中 “student” 为表名称,
“id”、“name”、“age”、“id_number” 为字段名称,跟在字段名称后面的是字段的数据类型,
“UNSIGNED” 表示无符号,
“AUTO_INCREMENT” 表示自增,
"PRIMARY KEY (id)"表示设置 “id” 为业务主键,
"NOT NULL DEFAULT ‘无名’ " 表示默认不为空,且默认值为 “无名” 。
执行结果如下图:
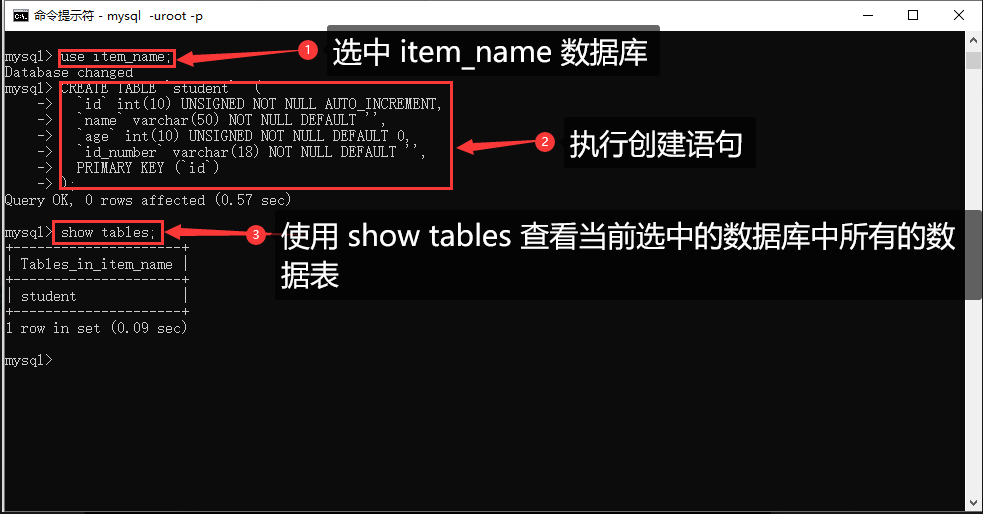
查看当前数据库中所有的数据表:
sql
命令:show tables可以看到 item_name 数据库中已经有了 student 这张数据表。
3.新建教师信息表 teacher
3.1 确定字段
| 字段名称 | 含义 |
|---|---|
| id | 自增主键 |
| name | 教师姓名 |
| age | 教师年龄 |
| id_number | 身份证号 |
3.2 选择字段的数据类型
| 字段名称 | 数据类型 |
|---|---|
| id | 无符号整型(UNSIGNED INT) |
| name | VARCHAR(50) |
| age | UNSIGNED INT |
| id_number | VARCHAR(18) |
3.3 新建数据表
命令 :
sql
CREATE TABLE `teacher` (
`id` int(10) UNSIGNED NOT NULL AUTO\_INCREMENT,
`name` varchar(50) NOT NULL DEFAULT '教师名',
`age` int(10) UNSIGNED NOT NULL DEFAULT 0,
`id_number` varchar(18) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
);NOTE
其中 “teacher” 为表名称,
“id”、“name”、“age”、“id_number” 为字段名称,跟在字段名称后面的是字段的数据类型,
“UNSIGNED” 表示无符号,
“AUTO_INCREMENT” 表示自增,
“PRIMARY KEY (id)” 表示设置 “id” 为业务主键,
"NOT NULL DEFAULT 教师名’ "表示默认不为空,且默认值为 “教师名” 。
执行结果如下图:
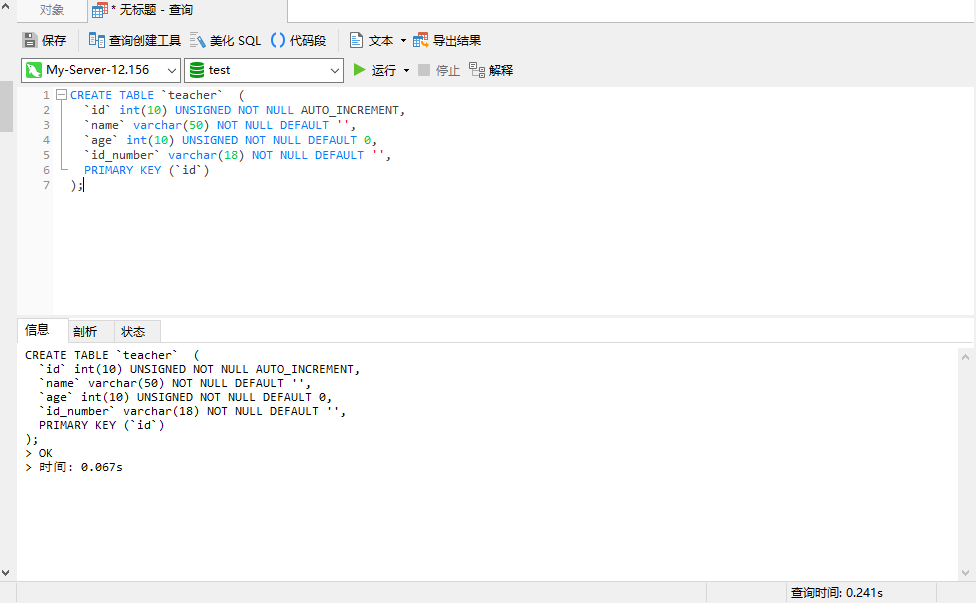
这里展示了使用 Navicat 来执行 sql 语句,选择数据库只需点击相应的数据库名称,然后选择新建查询即可。
4.新建课程表 course
4.1 确定字段
| 字段名称 | 含义 |
|---|---|
| id | 自增主键 |
| course_name | 课程名称 |
| teacher_id | 教师id |
4.2 选择字段的数据类型
| 字段名称 | 数据类型 |
|---|---|
| id | 无符号整型(UNSIGNED INT) |
| course_name | VARCHAR(50) |
| teacher_id | 无符号整型(UNSIGNED INT) |
4.3 新建数据表
命令 :
sql
CREATE TABLE `course` (
`id` int(10) UNSIGNED NOT NULL AUTO\_INCREMENT,
`course_name` varchar(50) NOT NULL DEFAULT '',
`teacher_id` int(10) UNSIGNED NOT NULL DEFAULT 0,
PRIMARY KEY (`id`)
);执行结果如下图:
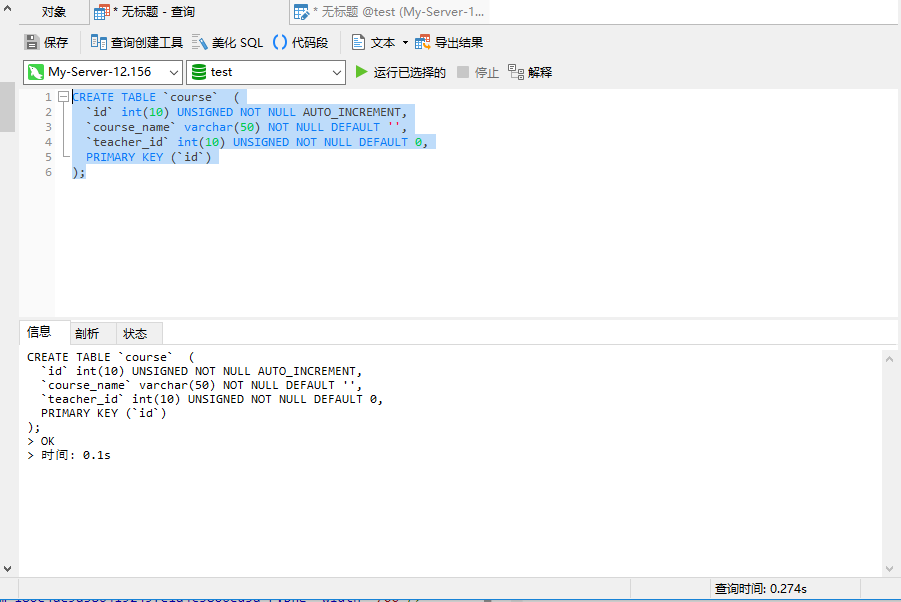
5.新建学生选课关联表 student_course
5.1 确定字段
| 字段名称 | 含义 |
|---|---|
| id | 自增主键 |
| student_id | 学生id |
| course_id | 课程id |
5.2 选择字段的数据类型
| 字段名称 | 数据类型 |
|---|---|
| id | 无符号整型(UNSIGNED INT) |
| student_id | 无符号整型(UNSIGNED INT) |
| course_id | 无符号整型(UNSIGNED INT) |
5.3 新建数据表
命令 :
sql
CREATE TABLE `student_course` (
`id` int(10) UNSIGNED NOT NULL AUTO\_INCREMENT,
`student_id` int(10) UNSIGNED NOT NULL DEFAULT 0,
`course_id` int(10) UNSIGNED NOT NULL DEFAULT 0,
PRIMARY KEY (`id`)
);执行结果如下图:
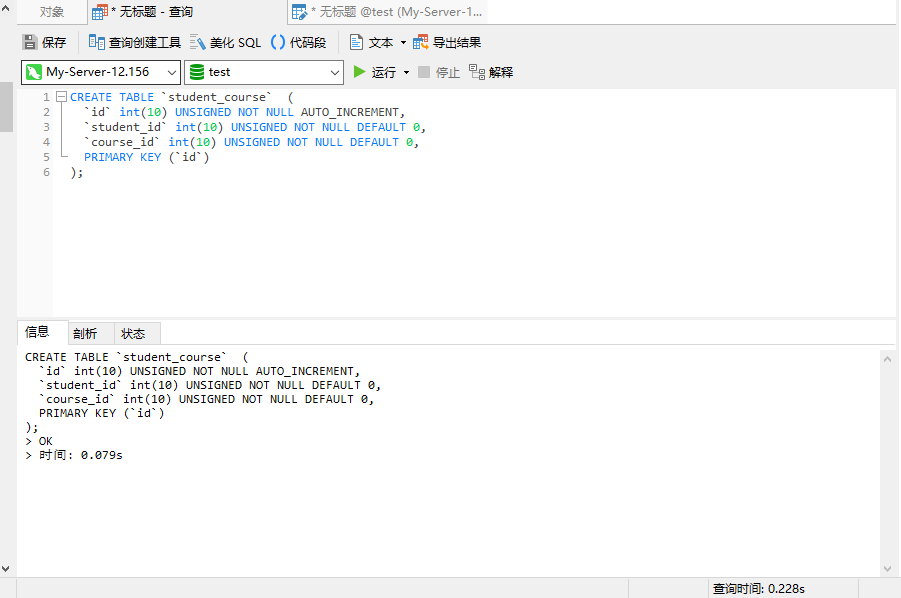
NOTE
需要注意的是每一张表都必须有一个主键,一般建议选定为无符号整型 id 作为主键,并且 id 一般作为主键一般设置为自增的(特殊情况可使用其他非自增 id 作为主键)
数据表设计规范
1.第一设计范式
通俗理解即一个字段只存储一项信息,如下图所示,其中联系方式可以拆分为手机、邮箱、固定电话,所以下图不符合数据表第一设计范式要求:
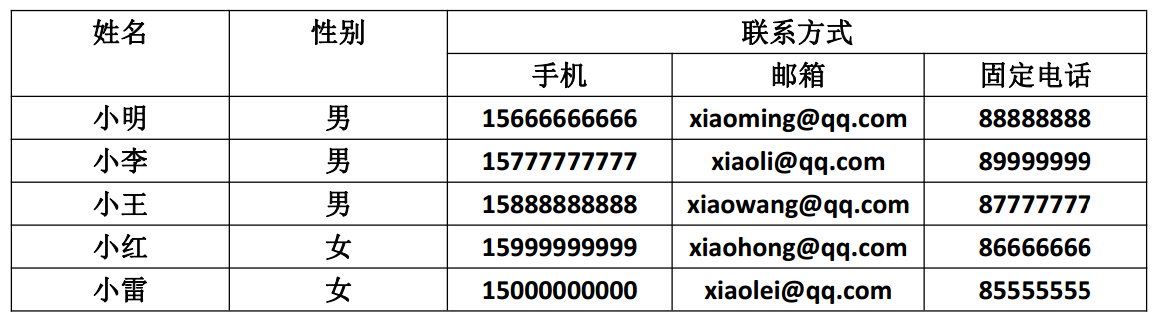
纠正之后符合第一设计范式要求的如下图所示:
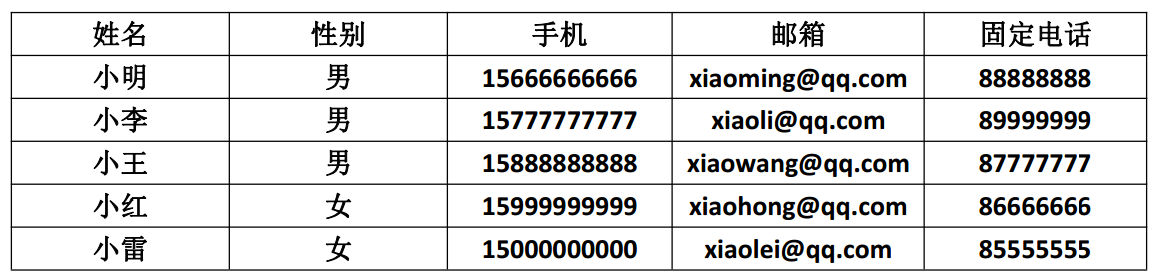
2.第二设计范式
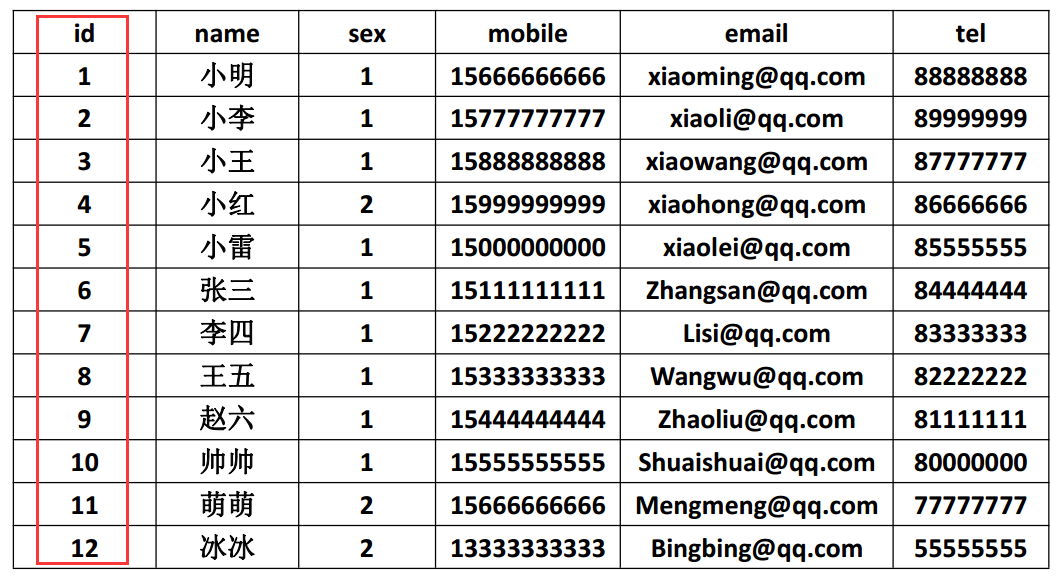
第二设计范式要求表中必须存在业务主键,并且全部非主键依赖于业务主键。通俗理解是任意一个字段都只依赖表中的同一个字段。(涉及到表的拆分)。如下图数据表字段中 id 即为业务主键:
3.第三设计范式
通俗解释就是一张表最多只存两层同类型信息。
如下图所示的商品表不符合第三设计范式:
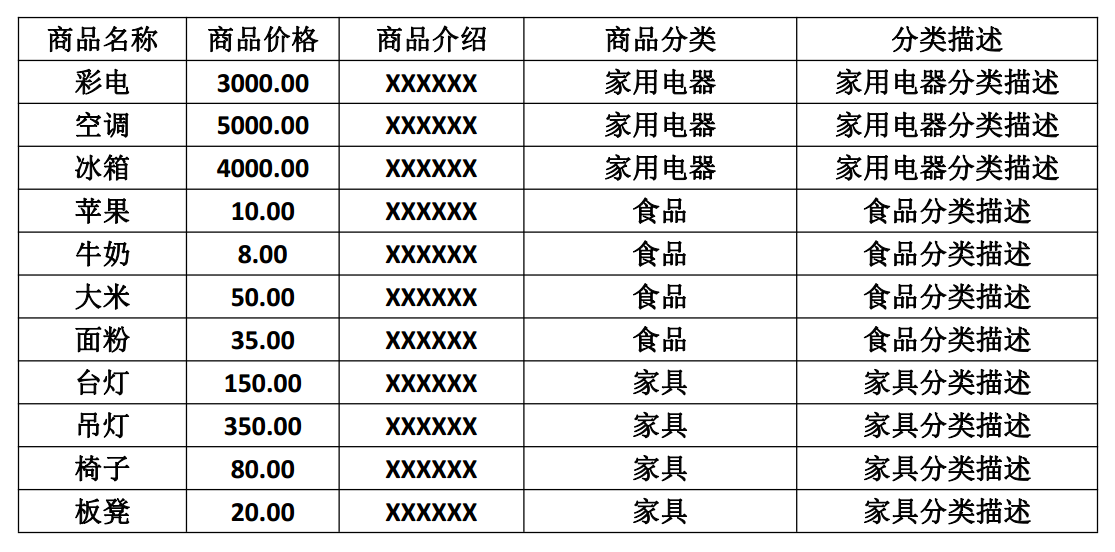
如图所示,商品分类和分类描述字段冗余,每次添加相同分类商品都会使数据重复,浪费存储空间,可以将表拆分成如下三个表:
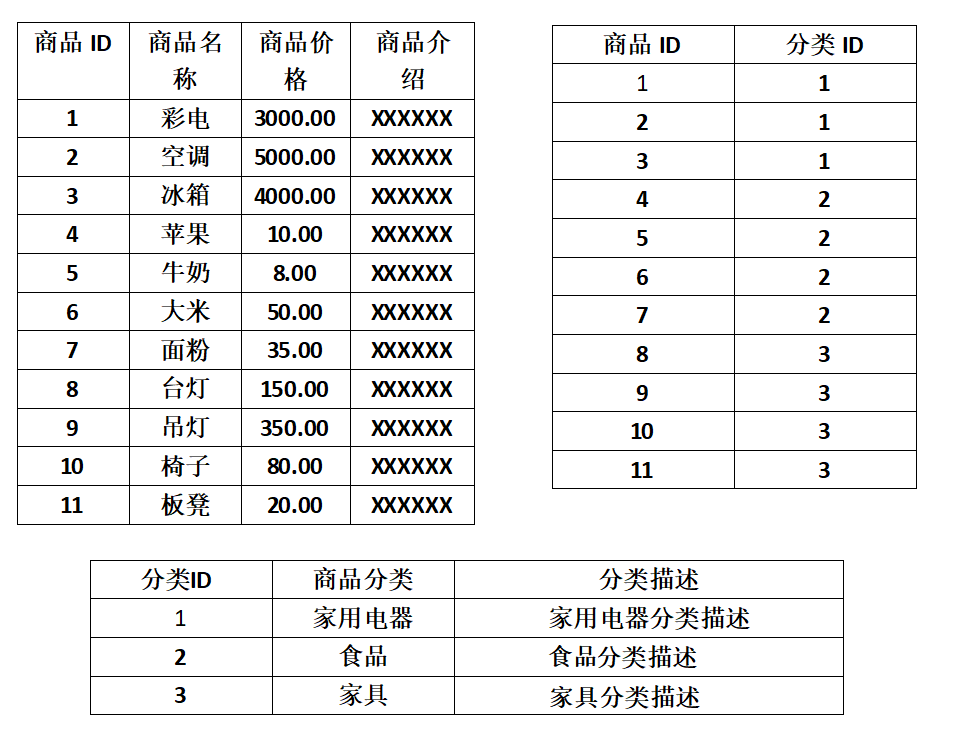
遵循数据表设计三范式可以避免字段值的重复存储,提升存储效率,节省存储空间,将各个数据之间分的更细,增加表的冗余性,为后期维护和拓展打下坚实的基础。
4.反范式化设计
没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,提高读性能,就必须降低范式标准,适当保留冗余数据。具体做法是: 在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,减少了查询时的关联,提高查询效率,因为在数据库的操作中查询的比例要远远大于 DML 的比例。但是反范式化一定要适度,并且在原本已满足三范式的基础上再做调整的。
如下图所示,上面的例子可以稍微反范式化设计一下,可以减少实际数据查询的连表查询操作,提升效率:
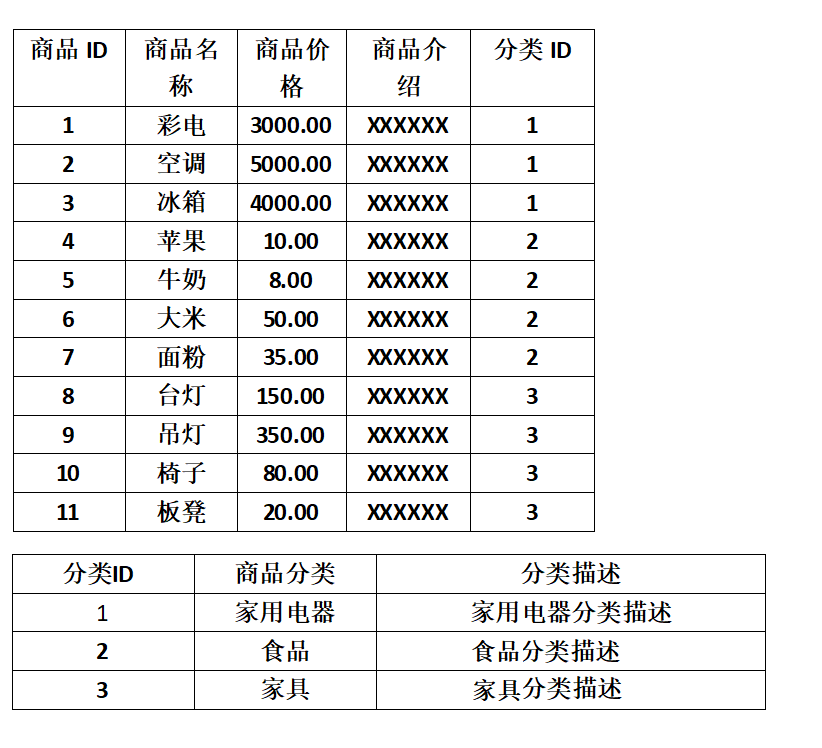
适当反范式化设计可以提升
查询效率和工作效率